February 29, 2024
Introduction
With the range of use cases for machine learning expanding a lot in recent years, the need to scale the operations around the training, deployment and monitoring of these models has also become quite important. Many of these concerns are similar to the ones that have been “solved” for general software use cases. Kubernetes is one such piece of open source software that has consolidated the cloud native eco-system around itself by serving as the underlying platform.
Hence, it becomes imperative to explore whether it is useful for kubernetes to be leveraged for a machine learning use case. Lets first start with kubernetes itself and whats so interesting about it.
What is kubernetes?

Credit: Kubernetes
💡 Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications.
In simpler terms, Kubernetes provides a simple and standardized way to run and operate workloads that need to be dynamically scaled across multiple machines.
Lets go through some of the most popular features -
- Automated deployments - Kubernetes provides a simple way of deploying a docker image using just a few lines of yaml. This gets us a declarative way of managing what we deploy and how we serve it. It also makes it super easy to make a robust CI pipeline on top of this abstraction.
- Service discovery - Services are natively allowed to call each other using static domain names. This makes it possible to not worry about the location of the other service and enables autoscaling.
- Load Balancing - Load balancing of requests intended for a particular service to all its instances distributed across multiple nodes is also taken care of. You can also attach an external load balancer from the cloud provider for internet facing services. This enables dynamic autoscaling, graceful failover and zero-downtime rollouts
- Self-healing - The built-in health checking mechanism keeps a watch over a running service and attempts to recover on failure by restarting the workload. This, combined with native load balancing support, is a huge win for the reliability aspect for any service.
- Autoscaling - Autoscaling the workload size up or down on the basis of actual resource consumption. This translates into critical cost savings for workloads that face a variable load.
- Developer Platform - Kubernetes has been built with the intention of serving as a platform for collaboration across multiple teams. This is enabled by native support for user and role management and multi-tenancy. These features become absolutely critical beyond a certain scale.
- Extensible - With a system of custom resources and controllers, kubernetes acts as a platform for other tooling that massively enhance the feature set. This effectively unlocks a whole host of use cases that are addressed by other tools. Ex - ArgoCD for GitOps, Istio for Service mesh, Kubeflow for ML pipeline orchestration etc
- Open Source - Kubernetes being open source means you get a huge range of options from running on bare metal servers to using one of the managed options from any major cloud provider. Aligning close to kubernetes means you get an interface that provides enough portability for the workload to actually be moved around according to business needs.
These are just some of the features that are available by default. A large number of use cases are actually solved by the tooling built using kubernetes as the underlying layer. We will get into specific tools in a subsequent issue.
Data scientist workflow overview
With the understanding of what kubernetes is and what are the major features it provides in a software development scenario, let’s delve into what are the specific problems that it can solve in a data scientist workflow.

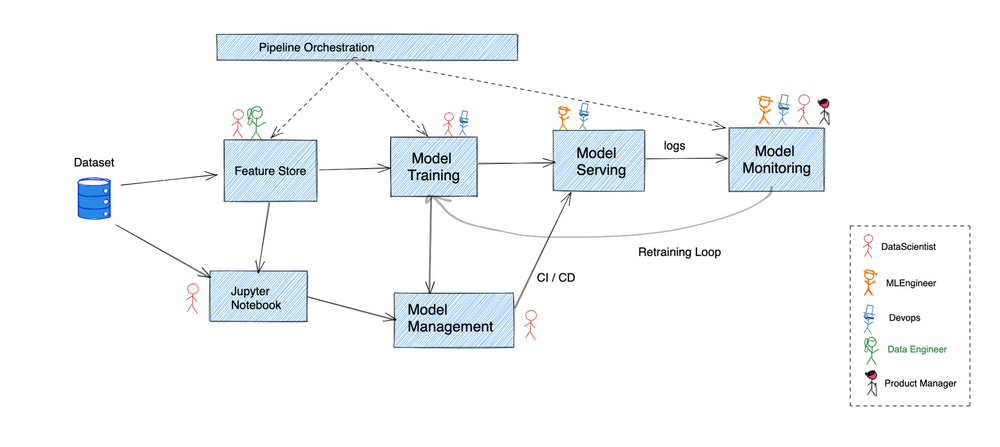
The figure above gives a broad outline of how a typical data science pipeline runs. A lot of companies have chosen to use a vast variety of bespoke solutions with overlapping features to glue it all together.
We’ll go through each of these steps to try and make sense of where kubernetes fits the bill -
Feature store
Before any raw data can be made useful, it must first be transformed into sanitised inputs for the model training pipeline. This is where feature stores come into the picture by performing transformation, storage and serving of the feature data.
Kubernetes supports deployment of stateful workloads and integrates very well with cloud providers to seamlessly provide persistence.
Model Development
Most model development starts with an ML Engineer writing code in a jupyter notebook and for many that is almost all that is needed. It provides a REPL interface for running python code. This starts with being hosted on personal laptops, but it is better to run a centralised pool of hosted jupyter notebooks which can be used by multiple individuals.
The declarative model of kubernetes along with support for persistent storage systems make it trivial to host a pool of notebooks and allow access control over individual notebooks to enforce effective collaboration.
Model training
Any algorithm written on a notebook needs to be fed training data to get a model artefact as an output. This can be done in the notebook itself in smaller use cases but requires a much more powerful pipeline for larger datasets. Usually the validation against test data set is also performed here before the artefact is used for performing inferences in production.
There are multiple solutions for orchestrating a DAG pipeline on kubernetes. Airflow has native support for kubernetes while kubeflow has been built completely on top of kubernetes. All the major monitoring solutions provide first class integration with kubernetes which is essential for running production grade pipelines.
Model management
This stage takes care of storing and versioning the dataset and the model. This ensures that any model artefact remains reproducible for as long as needed. A parallel can be drawn to how code management is performed using git.
Although the underlying data store for such management systems can be hosted on kubernetes itself, in many cases it is better to use a managed solution from a cloud provider. In such cases, most of the cloud providers seamlessly integrate their own IAM systems with that of kubernetes making it safe to access data from outside the cluster without having to store the access credentials.
Model Serving
Finally, the model artefact is prepared so that a production system can make inferences on top of it. This usually involves wrapping a model in an API framework and allowing other services to call the model to make inferences. Concerns similar to software engineering such as authn/authz, scalability, reliability etc come into the picture here.
This is where kubernetes shines. Most of the features that we talked about in the earlier section become critical at this stage.
Model monitoring
Like any production system, continuously monitoring the currently deployed model is essential to make sure that your system is behaving the way it is expected to. The metrics to watch out for can include everything from the actual accuracy of the predictions to the latency and throughput the system is able to support.
A lot of monitoring solutions integrate closely with kubernetes. Discovering a target to actually scrape metrics, performing computation on top of it and storing it for later use can all be performed without any external dependency.
Conclusion
The whole landscape around kubernetes has been exploding and a lot of tooling is already out there. There are however some pitfalls that any organisation should keep in mind before adopting it wholesale. We’ll get into those and how they can be mitigated in the next issue.

Subscribe to our Newsletter

Delivered twice a month
Join AI/ML leaders for the latest on product, community, and GenAI developments

%20(11).png)