February 29, 2024
Machine Learning on Kubernetes #2: Kubernetes Architecture for MLOps

March 27, 2023
Share this post

Machine learning operations (MLOps) is a critical component of modern data science workflows. MLOps involves the development, deployment, and management of machine learning models and associated infrastructure. One of the key challenges of MLOps is the need for scalable and flexible infrastructure that can accommodate the unique requirements of ML workloads. Kubernetes is a powerful platform that can provide the necessary infrastructure to support MLOps at scale. However, designing a Kubernetes architecture for MLOps requires careful consideration of factors such as security, resource management, and application dependencies. In this blog, we will explore some best practices for designing a Kubernetes architecture for MLOps.
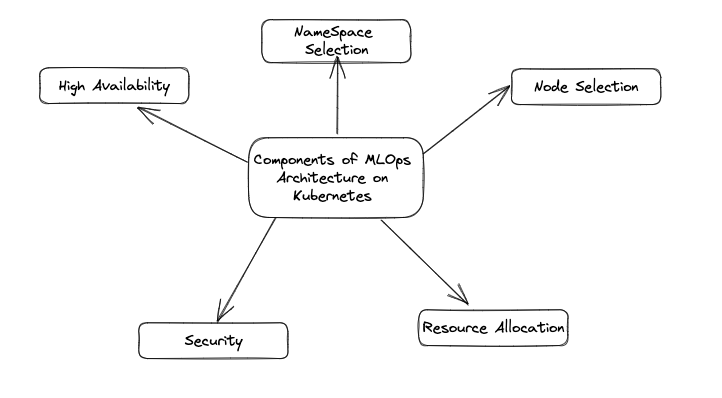
Namespace Design
Kubernetes namespaces provide a way to partition resources within a cluster. In an MLOps architecture, it is common to use namespaces to separate different environments such as development, testing, and production. This helps ensure that applications and services are isolated from each other and reduces the risk of resources/application conflicts. Effective namespace design can also improve overall cluster performance and resource utilisation.
When designing namespaces for MLOps, consider the following:
- Use descriptive names that reflect the purpose of the namespace (e.g., "dev", "test", "prod").
- Use RBAC (role-based access control) to restrict access to namespaces based on user roles.
- Use resource quotas to limit the amount of CPU and memory that can be used by applications in each namespace
Node Selection
Kubernetes uses a scheduling algorithm to determine which nodes to use for deploying applications. Proper node selection can ensure optimal performance and reduce the likelihood of performance and network latency issues.
When designing a Kubernetes architecture for MLOps, it is important to consider the following factors when selecting nodes:
- The type and amount of resources required by applications (e.g., CPU, memory, GPU).
- The network latency between nodes and the data storage location.
- The location of any specialized hardware required for machine learning workloads.
To optimize node selection, you can use tools such as node selectors, node affinity, and taints and tolerations. For example, you can use node selectors to specify which nodes are suitable for machine learning workloads that require GPUs.
Example Illustration: Suppose you have a large dataset that you need to train a machine learning model on, and you want to use a distributed training approach to speed up the process. You decide to use TensorFlow and run the training job on a Kubernetes cluster. To optimize the performance of the training job, you want to make sure that the nodes you select for running the job have the right combination of CPU, GPU, memory, and storage resources. For example, you might want to select nodes that have GPUs with a certain amount of memory, or nodes that have SSD storage for faster data access.
How to use Node selectors and affinity for the above scenario?
In this scenario, you could use node labels and node selectors in Kubernetes to ensure that your ML training job runs on nodes with the right combination of resources. You could label nodes in the cluster based on their hardware specifications, such as CPU type, GPU type, memory size, and storage type, and then use node selectors in your training job specification to specify which nodes to use.
For example, you could define a node selector in your TensorFlow job specification that selects nodes with a certain combination of labels, such as "CPU=Intel" and "GPU=Nvidia" and "Memory>=32GB". This would ensure that your training job runs on nodes with the right hardware specifications, which would optimize the performance of the job and reduce the time required for training the model.
Alternatively, you could use Kubernetes node affinity and anti-affinity rules to specify more complex scheduling requirements, such as scheduling pods only on nodes that have a certain set of labels or avoiding scheduling pods on nodes that have certain labels. This would provide more fine-grained control over the scheduling of your training job and could help ensure that it runs on the most suitable nodes for the task.
Resource Management
Managing resources is critical to ensuring that applications and services run smoothly and effectively on Kubernetes. It also helps prevent performance issues and reduces the likelihood of failures
When designing a Kubernetes architecture for MLOps, consider the following best practices for resource management:
- Use resource requests and limits to specify the amount of CPU and memory required by applications.
- Use horizontal pod autoscaling (HPA) to automatically scale the number of replicas based on CPU or memory utilization.
- Use Kubernetes native tools such as kube-top, kube-state-metrics, and Prometheus to monitor resource usage.
High Availability
In an MLOps architecture, high availability is essential to ensure that services are always available to users even in event of failures, thus improving the reliability of Machine learning workloads and reducing the likelihood of outages
To achieve high availability on Kubernetes, consider the following:
- Use multiple replicas of critical applications to ensure that they can survive node failures.
- Use a load balancer to distribute traffic to multiple replicas.
- Use Kubernetes native tools such as readiness probes and liveness probes to detect and recover from application failures.
Example Illustration: Suppose you are a SaaS company that provides an ML-based recommendation engine to your customers. Your recommendation engine uses a deep learning model that requires a significant amount of computing resources to train and run. You need to ensure that your ML workload is highly available and that you can allocate resources effectively to handle fluctuations in demand.
Managing Resources and ensuring High availability using internal kubernetes features
To manage your resources effectively, you could use Kubernetes' built-in resource management features, such as resource requests, limits, and quotas. You could define resource requests and limits for each component of your recommendation engine, such as the web server, the database, and the machine learning model. This would ensure that each component is allocated the right amount of resources to function efficiently and that resources are not wasted on over-provisioning.
In addition, you could set up a horizontal pod autoscaler (HPA) in Kubernetes that automatically scales your recommendation engine based on demand. The HPA would monitor the resource utilization of your workload and adjust the number of replicas of each component to match the demand. This would ensure that you have the right amount of resources available to handle fluctuations in demand and that you are not over or under-provisioning.
To ensure high availability of your workload, you could deploy your recommendation engine across multiple availability zones (AZs) in your cloud provider's infrastructure. You could use Kubernetes' node affinity and anti-affinity rules to ensure that each component of your workload is distributed across multiple AZs. This would ensure that if one AZ goes down, your workload would continue to function, ensuring high availability.
In addition, you could set up a load balancer to distribute traffic to the different replicas of your web server component, ensuring that traffic is balanced across all available replicas. This would prevent any single replica from becoming overloaded and ensure that your workload can handle high levels of traffic.
Security
Security is a critical consideration when designing a Kubernetes architecture for MLOps and can help ensure that machine learning workloads and associated data are protected from unauthorized access and data breaches
"Security is not just an afterthought for machine learning, it is a core part of the development process. From data collection to model deployment, every step of the ML pipeline needs to be considered from a security perspective. This is especially true when dealing with sensitive data or when deploying models in production environments where they are exposed to potential attackers. As ML practitioners, we need to be proactive in identifying and mitigating security risks, and continually evaluate our security posture as new threats emerge."
-Dr. Tracy Hammond, Professor of Computer Science and Engineering at Texas A&M University and Director of the Sketch Recognition Lab
To ensure that your infrastructure is secure, consider the following best practices:
- Use RBAC to restrict access to resources based on user roles.
- Use network policies to restrict traffic between namespaces and pods.
- Use secrets management tools such as Vault or Kubernetes Secrets to store sensitive data such as API keys and passwords.
- Use container images from trusted sources and scan them for vulnerabilities using tools such as Clair or Trivy.
Conclusion
In conclusion, Kubernetes provides a powerful platform for implementing MLOps infrastructure that can accommodate the unique requirements of ML workloads. By carefully considering the design of namespaces, node selection, and resource management, ML practitioners can ensure that their ML workloads are running efficiently, securely, and with high availability. With the growing demand for scalable and flexible infrastructure for ML workloads, Kubernetes is a valuable tool for MLOps practitioners who want to stay ahead of the curve. We hope this blog has provided you with a useful introduction to implementing MLOps infrastructure on Kubernetes, and we encourage you to explore this powerful platform further to support your own ML workflows.
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.

Subscribe to our Newsletter

Delivered twice a month
Join AI/ML leaders for the latest on product, community, and GenAI developments

%20(11).png)