April 16, 2024

Deploying open-source Large Language Models (LLMs) at scale while ensuring reliability, low latency, and cost-effectiveness can be a challenging endeavor. Drawing from our extensive experience in constructing LLM infrastructure and successfully deploying it for our clients, I have compiled a list of the primary challenges commonly encountered by individuals in this process.
Key Issues in Deploying LLMs
Find the most optimal way to host one instance of the model
There are multiple options for model servers to host LLM and various configuration parameters to tune to get the best performance for your use case. TGI, VLLM, OpenLLM are a few of the most common frameworks for hosting these LLMs. You can find a detailed analysis in this blog. To choose the right framework for your hosting, its important to benchmark the performance of these frameworks for your usecase and choose the one that suits your usecase the best. Also, these frameworks have their only tunable parameters that can help you extract the best benchmarking results.
Finding the fleet of GPUs
GPUs are expensive and hard to find. There are various GPU cloud providers ranging from prominent clouds like AWS, GCP and Azure to small-scale cloud providers like Runpod, Fluidstack, Paperspace, and Coreweave. There is a wide variation in the prices and offerings of each of these providers. Reliability also remains a concern with some of the newer GPU cloud providers.
Maintaining reliability
This in practice is harder than it sounds. From our experience of running LLMs in production, you should be prepared for weird one-off bugs in model servers that can leave your process hanging and all requests to time out. It is very important to have proper process managers and readiness/liveness probes set up so that the model servers can recover from failures or traffic can shift seamlessly from an unhealthy to a healthy instance.
Ensuring high throughput at low latency
While benchmarking, it is very important to figure out the tradeoff between latency and throughput. As we increase the number of concurrent requests to the model, the latency will go up slightly till a certain point, after which latency deteriorates drastically. Finding the correct balance between latency, throughput and cost can be time-consuming and error-prone. We have a few blogs outlining such benchmarks for Llama7B and Llama13B.
Ensure Fast Startup time of the model
LLM Models are huge in size - ranging from 10s to 100GB. It can take a lot of time to download the model once the model server is ready, and then to load it from disk to memory. Its essential that you cache the model on disk so that we don't end up downloading the model again in case the process restarts. Also to save network costs, its better to download the model once and share the disk among multiple replicas instead of each replica repeatedly downloading the model over internet.
Setup autoscaling
Autoscaling is tricky in case of LLM hosting because of the high startup time of another replica. If the load is very spiky, we usually need to provision infrastructure according to the peak replicas - however if the peak is expected within certain times of the day, time based autoscaling works out well.
How to take LLMs to production?
- Start with benchmarking the LLM with different model servers, GPU, and parameters to see where you get the best performance. Ideally, you should have data from benchmarking similar to what we have in this blog for Llama7B.
- You can set up models on multiple GPUs on Kubernetes or on bare metal instances. We would ideally recommend Kubernetes because you get all the health checks, routing and failover for free.
- Put the model in a shared volume like EFS so that models are not downloaded repeatedly and mount the volume to all the pods.
- Setup monitoring and alerting on the instances.
- Ideally have a layer that can do the token counting for you in every request since its easier to understand the pattern of traffic coming in.
- Observe the traffic pattern and adjust the autoscaling policy accordingly.
- Keep a mix of spot and on-demand instances to lower costs.
Architecture for hosting LLMs on Scale
We started with the above approach, however soon migrated to the architecture below which allows us to host LLMs with very low costs and high reliability.
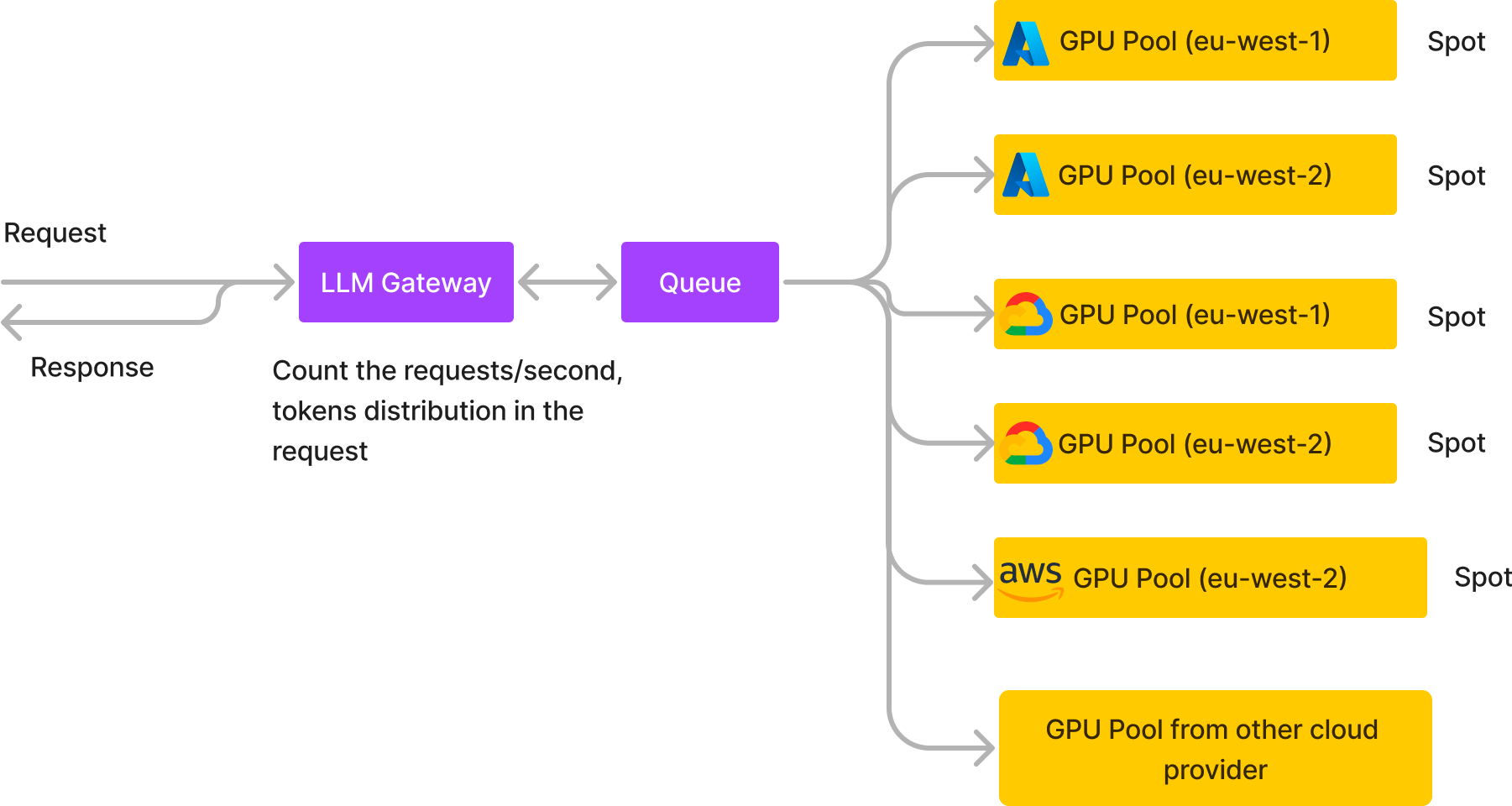
We basically create multiple GPU pools on different cloud providers in different regions and we usually use spot instances if its one of AWS, GCP or Azure or on-demand nodes from the smaller cloud providers. We also put a queue in the middle which takes in all the requests and the different GPU pools consume from the queue and return the response back to the queue from where the HTTP response is returned to the user. A few advantages of this architecture:
- High reliability with spot instances: Because we are distributing the load across spot instances from multiple cloud providers and regions, chances of all spot instances going down becomes extremely slow and each of the pools can grow to take in the load when one pool goes down.
- Queue adds extra reliability under high load: An HTTP service will start returning 503s if there are sudden spikes. Because of the queue in between, we are able to tolerate spiky workloads - there is a slight increase in latency for the requests during the spike, but they don't fail. Adding the queue in the middle adds an overall latency of around 10-20 ms which is fine for LLM inference usecase since the overall inference latency is in the order of seconds.
- Cost Reduction: This helps reduce the cost drastically compared to hosting LLMs on on-demand instances - we will do a detailed comparison below of the costs.
- Detailed analytics: The LLM gateway layer helps us calculate the detailed analytics about the incoming requests and can also calculate the token distribution among the requests. We can also start logging the requests to enable finetuning later.
- No dependency on one cloud provider: This architecture allows us to easily swap our one GPU provider with another if we find a better price somewhere with zero downtime. Also in case one provider goes down, the other pools keep the system up and running smoothly!
Cost Reduction for hosting LLMs
Let's take a scenario of hosting an LLM with 10 requests per second at peak and 7 requests per second on average. Lets say we figure out using benchmarking that one A100 80GB GPU machine can do 0.5 RPS. Let's also consider that the traffic is more for 12 hours a day (around 9-10 RPS) and low for the rest 12 hours in a day (7-8 RPS).
Based on the above data, we can find the number of GPU machines needed at peak 12 hours window and non peak 12 hours window:
Peak 12 hours window: 20 GPU
Non peak 12 hours window: 15 GPU
We will compare the cost of running the LLM using Sagemaker, naively hosting on on-demand machines in AWS, GCP and Azure and using our own architecture with autoscaling.
Cost of hosting on Sagemaker (us-east-1 region):
Cost of 8 A100 80GB machine (ml.p4de.24xlarge) -> $47.11 per hour
We will need 2 machines during non-peak hours and 3 machines during peak hours.
Total monthly cost: $85K
Cost of hosting on AWS nodes directly:
Cost of 8 A100 80GB machine (p4de.24xlarge) -> $40.966 per hour
We will need 2 machines during non-peak and 3 machines during peak hours:
Total monthly cost: $73K
Cost of hosting on Truefoundry
Using the spot instances and other GPU providers, we are able to get the average GPU pricing down to $2.5 an hour. Assuming 15GPU during non-peak hours and 20 GPU during peak hours, the total cost will be:
$2.5 * (15*12 + 20*12) * 30 (days a month) = $31K
As we can see, we are able to host the same LLM at almost 30% the price of the Sagemaker with high reliability. However, it will require efforts to build and maintain this architecture. Truefoundry can help host it for you or host it on your own cloud account with zero hassle while saving costs at the same time.

Subscribe to our Newsletter

Delivered twice a month
Join AI/ML leaders for the latest on product, community, and GenAI developments