May 3, 2024

The ChatGPT moment of the open source world is here- Meta released its latest set of open-source large language models, called Llama 2 - a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters.
Fun Facts & Mnemonics about Llama 2
- Llama 2 is trained on publicly available online data with roughly 2T tokens. This is >300x the entire English wikipedia.
- Llama 2 has been trained on 1M human annotations- compare it with 15k labeled datasets for Dolly by Databricks.
- Time to train the 7B, 13B & 70B variants is reported as 184k, 368k & 1.7M GPU hours with A100-80GB. This interestingly approximates to about 1000 GPU-weeks for every 1B parameters. So 70 weeks of training if you were using 1000 GPUs in parallel for the 70B model.
- The GPU cost only to train these models would be about $800k, $1.5M and $8M respectively. A total of $10M worth of GPUs for the final run! :)
- The pre-training data is static and upto date until Sep 2022, but it has been fine tuned with latest data until July 2023.
- The context window is 4k for the 3 variants 7B, 10B & 70B.
Why should you care?
- Well, for starters, this is available to use for free for research and commercial purposes- first of its kind model with quality like ChatGPT, backed by a big tech, and available to be deployed & fine tuned today. (Unless, you have >700M monthly active users in the preceding calendar month in which case you need to procure a license from Meta to use it!)
- The fine-tuned versions, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks, and are on par with some popular closed-source models like ChatGPT and PaLM in the human evaluations for helpfulness and safety.
- For all those, who have been waiting for legal and compliance approvals in using commercial closed-source services like OpenAI, and were underwhelmed by the quality of response of the previous generations of Open Source LLMs- you have your answer. More importantly, it's a reinforcement on how Open Source LLMs are here to stay and will continue to improve.
Quality Benchmarks of Llama 2
Llama 2 shows remarkable performance across various LLM benchmarks. Here’s a comparison between Llama and ChatGPT models:

Llama-2-70b-chat-hf model approaches or even surpasses the performance of GPT-3.5, the original ChatGPT model, on multiple benchmarks. You can find more details here. Details on the datasets & tasks in the appendix section.
Cost of using Llama 2 on a sample task
Many, who have put Open AI based applications in production are concerned about the bills and how sustainably they can scale up these applications. We did some comparison on what does it take to run a LLama 2 and how does it compare to some of the Open AI models.
Sample Task: Say we wanted to take the English wikipedia (6M articles, 1000 tokens each) and summarize them to half the size using LLMs. Detailed calculations can be found in this blog. Here are some interesting pointers on the cost of this task with various models here-
- Doing it with GPT-4 would cost about $360k.
- Same task with GPT-3 Davinci variant (175B parameteres) would be about $180K and if you used a fine-tuned variant of Davinci, that would be >$1M.
- Instead, if you used the Curie model (~7B parameters), the cost would $18K and the fine tuned cost would be ~$125k.
- Compare it with the equivalent size model Llama 2 (7B variant). It would cost ~$2k and the fine tuned version of it would cost ~$3k. That is about 9x and 40x difference in cost in comparable models between pre-trained and fine tuned versions respectively.
Deploying Llama-2-13b-chat model
The model is available to use through Microsoft Azure, AWS and Huggingface. You can also deploy Llama-2 models through TrueFoundry with minimal steps.
You need to have access to the Llama-2 models on Huggingface to deploy it on TrueFoundry. Find more information here. TrueFoundry model catalogue is updated with the best and the latest open-source LLMs. With the model catalogue, everything is pre-configured for deploying the models and you can deploy them to your own cloud infra with a single click. Llama-2 models will be shortly available on the model catalogue for one-click deployment. But meanwhile, TrueFoundry users can still deploy Llama-2 models as described below.
- From the deployments page, click on
New Deploymentand chooseService.
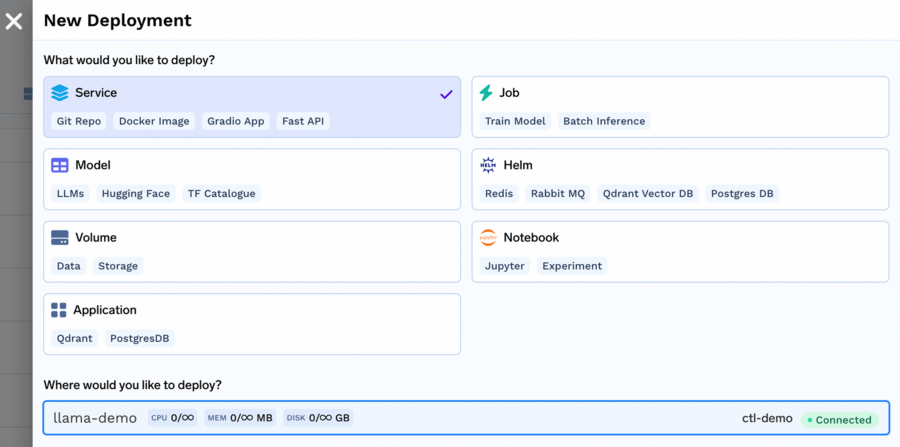
2. We can use Text Generation Interface library from Huggingface to deploy this model. Choose to deploy the text-generation-inference image (ghcr.io/huggingface/text-generation-inference:0.9) and override the command with command to launch required model (text-generation-launcher --model-id meta-llama/Llama-2-13b-chat-hf):

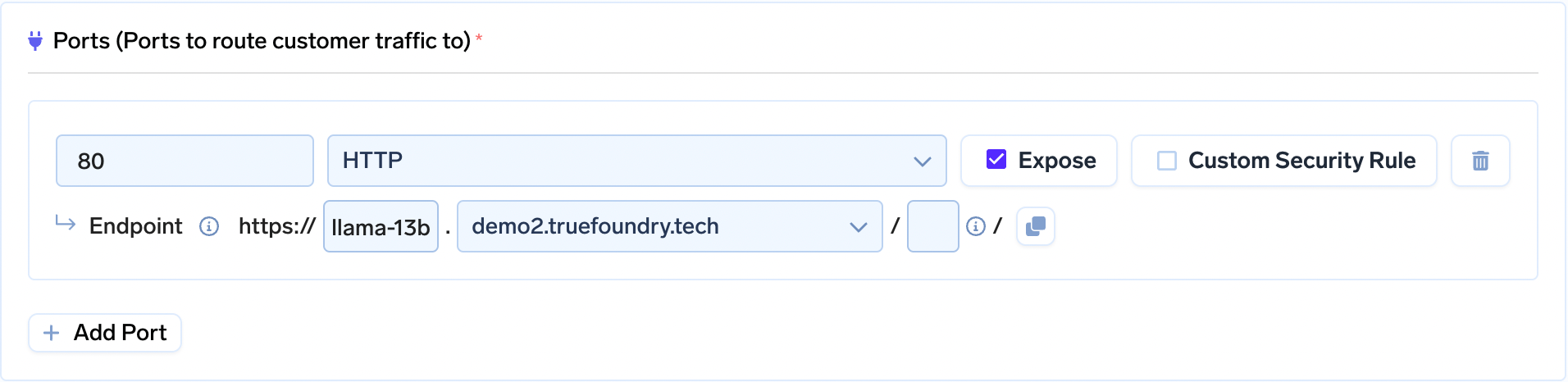
3. Now let’s set the model endpoint. The model will be served at port 80, so let’s expose that:
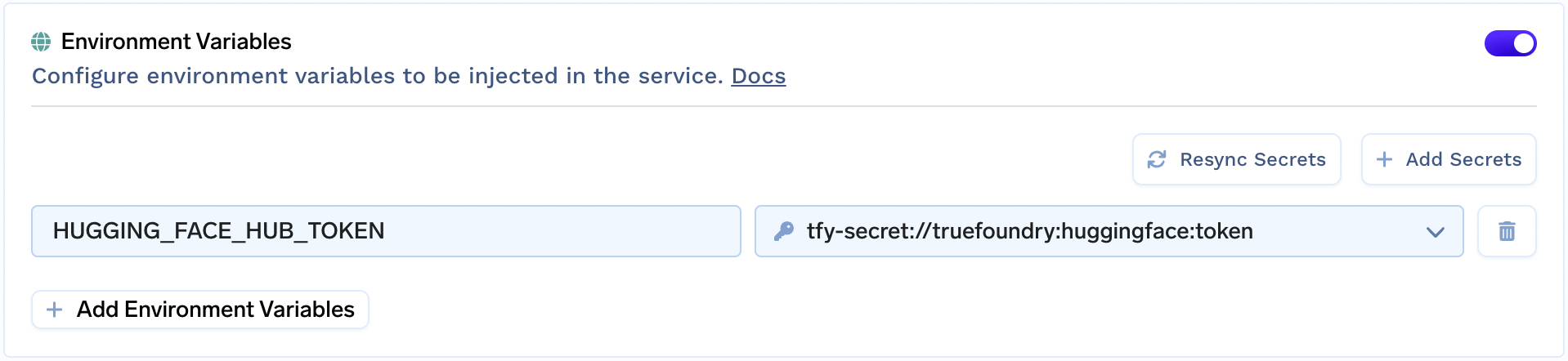
4. Since the Llama-2 models are only available through approved accounts, we need to set the Huggingface API key as an environment variable. The key should be HUGGING_FACE_HUB_TOKEN.
Note that in the image, we are indirectly using the Huggingface API key by creating a secret on TrueFoundry. You can also paste the value directly, but we do not recommend that.
5. Finally, we need to allocate resource as required by this model. I chose to deploy 13b-chat model version on a node with a A100 40GB. You can configure other values as follows:

6. Click Submit and your model will be deployed and available at the endpoint you set.
Make inference using the deployed model
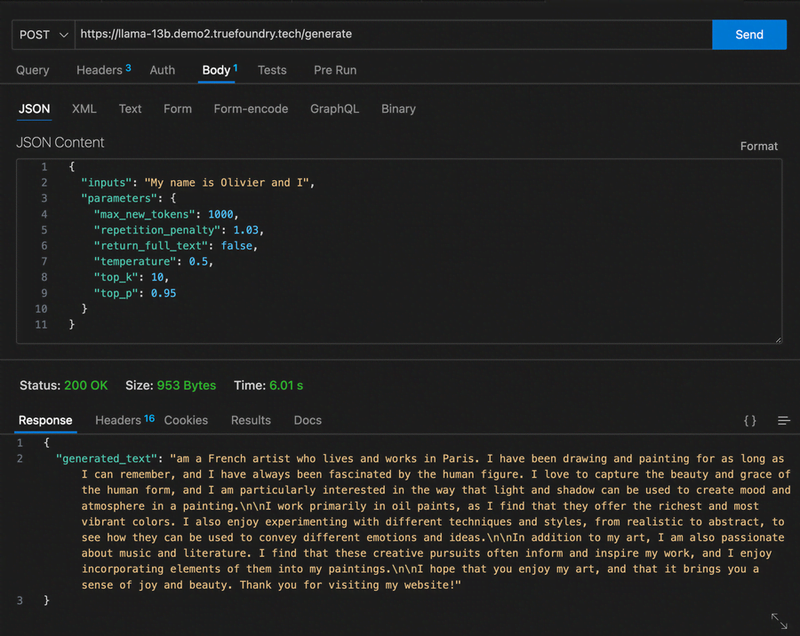
You can call the generate endpoint to get inferences using the model we just deployed. There’s also a Python library text-generation that you can use with your Python code to use the deployed model.
Using HTTP request:
Using Python Client:

You can find more info about the clients here.
TrueFoundry LLM Playground
The TrueFoundry LLM Playground can be used to prompt and compare model you have deployed on TrueFoundry and other models like ChatGPT. Once the Llama-2 model is deployed, we can also test it out through the TrueFoundry LLM Playground:

Chat with us
We are still learning about this topic, as everyone else. In case you are trying to make use of Large Language Models in your organization, we would love to chat and exchange notes.
Have a ☕️ with us
Appendix : Details about tasks & metrics
MMLU stands for Multi-task Multi-Lingual Language Understanding. It is a benchmark that measures the performance of language models on a variety of tasks, including question answering, natural language inference, and summarization. The intuition behind MMLU is that language models should be able to understand and process information in a variety of ways, and that they should be able to do this in multiple languages.
TriviaQA is a dataset of questions and answers about factual topics. It is used to measure the ability of language models to answer questions that require factual knowledge. The intuition behind TriviaQA is that language models should be able to access and process information from external sources, such as Wikipedia, in order to answer factual questions.
Natural Questions is a dataset of questions that are asked by humans about real-world information. It is used to measure the ability of language models to understand and answer natural language questions. The intuition behind Natural Questions is that language models should be able to understand the nuances of human language and to generate responses that are relevant and informative.
GSM8k is a dataset of 8,000 questions that are generated from Google Search queries. It is used to measure the ability of language models to understand and answer questions that are similar to those that people ask Google Search. The intuition behind GSM8k is that language models should be able to understand the intent of human queries and to generate responses that are relevant and informative.
HumanEval is a benchmark that measures the performance of language models on a variety of tasks by asking humans to evaluate the outputs of the models. The intuition behind HumanEval is that human evaluation is a necessary part of assessing the performance of language models, as it can help to identify areas where the models are still struggling.
AGIEval is a benchmark that measures the ability of language models to perform tasks that are typically associated with artificial general intelligence. The intuition behind AGIEval is that language models should be able to understand and reason about the world in a way that is similar to how humans do.
BoolQ is a dataset of questions that require boolean logic to answer. It is used to measure the ability of language models to understand and reason with logical statements. The intuition behind BoolQ is that language models should be able to understand the meaning of logical statements and to generate responses that are consistent with those statements.
HellaSwag is a dataset of questions that are written in a "swag" style, which is a type of informal language that is often used in social media. It is used to measure the ability of language models to understand and generate natural language in a variety of styles. The intuition behind HellaSwag is that language models should be able to understand and generate natural language that is appropriate for the context in which it is being used.
OpenBookQA is a dataset of questions that can be answered by consulting a large corpus of text. It is used to measure the ability of language models to access and process information from external sources. The intuition behind OpenBookQA is that language models should be able to access and process information from a variety of sources in order to answer questions.
QuAC is a dataset of questions that are asked about conversations. It is used to measure the ability of language models to understand and follow the context of a conversation. The intuition behind QuAC is that language models should be able to understand the context of a conversation and to generate responses that are relevant to the conversation.
Winogrande is a dataset of questions that are challenging for language models to answer. It is used to measure the ability of language models to understand and answer complex questions. The intuition behind Winogrande is that language models should be able to understand and answer complex questions that require a deep understanding of the world.

Subscribe to our Newsletter

Delivered twice a month
Join AI/ML leaders for the latest on product, community, and GenAI developments